
Have you ever wondered if an LLM that “reason” more deeply — one that’s been rigorously trained for complex problem-solving — would create better, more semantically rich text embeddings? If a model can reason its way through intricate logic puzzles, its internal representation of language and understanding of meaning, may be superior.
Prepare for a plot twist. Our latest research, “Do Reasoning Models Enhance Embedding Models”, reveals a fascinating paradox: the enhanced reasoning capabilities of models optimized with Reinforcement Learning with Verifiable Rewards (RLVR) do not consistently translate to superior semantic representations when these models are used as backbones for text embedding models.
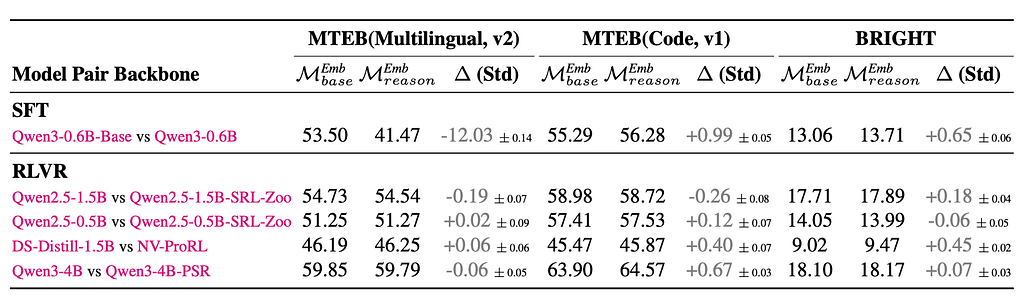
This isn’t just an unexpected result; it presents a scientific puzzle: Why do powerful reasoning models, after all that specialized training, yield embedding performance that’s statistically identical to their simpler, non-reasoning counterparts?
To crack this puzzle, we needed to look beyond traditional performance metrics, which can often mask deeper internal dynamics. We introduced Hierarchical Representation Similarity Analysis (HRSA) — a novel framework that lets us dissect how models represent information at three distinct levels:

What HRSA unveiled is a phenomenon we term Manifold Realignment.
Think of the latent manifold (your embedding space) like a meticulously organized library. Each book has its place, and the entire layout makes sense.
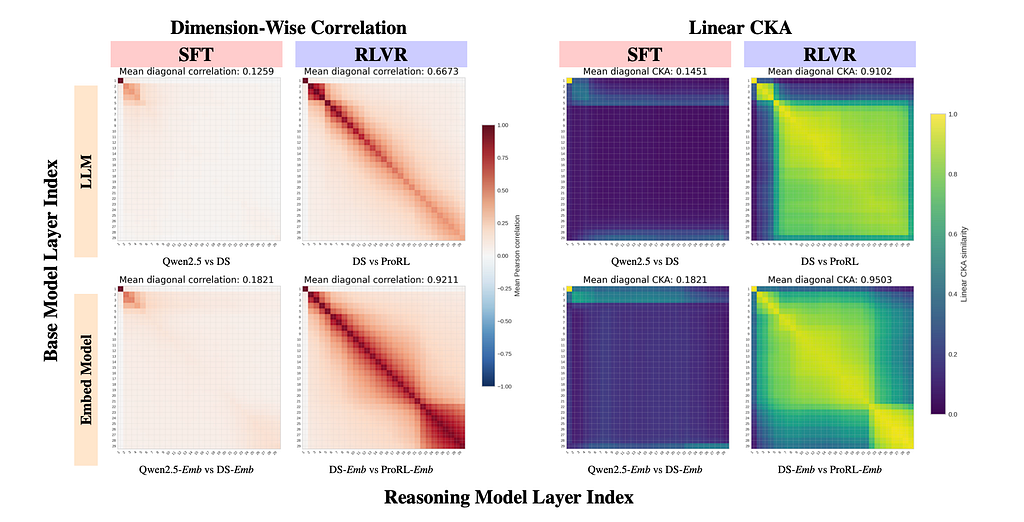
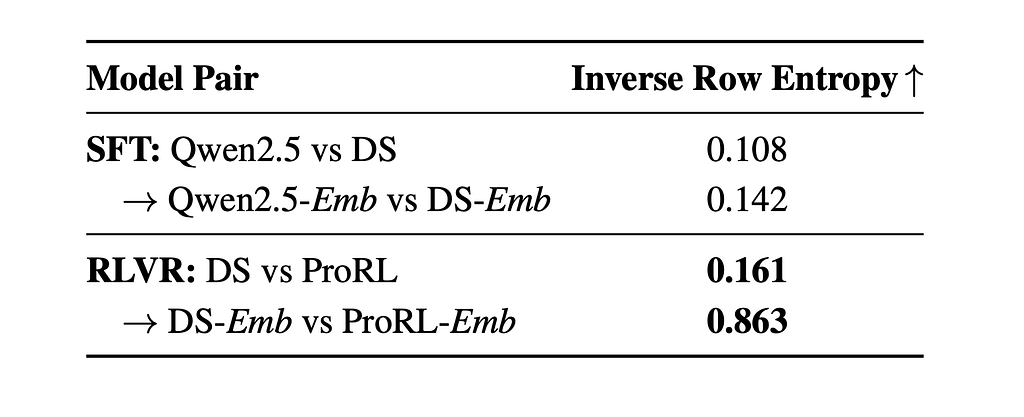
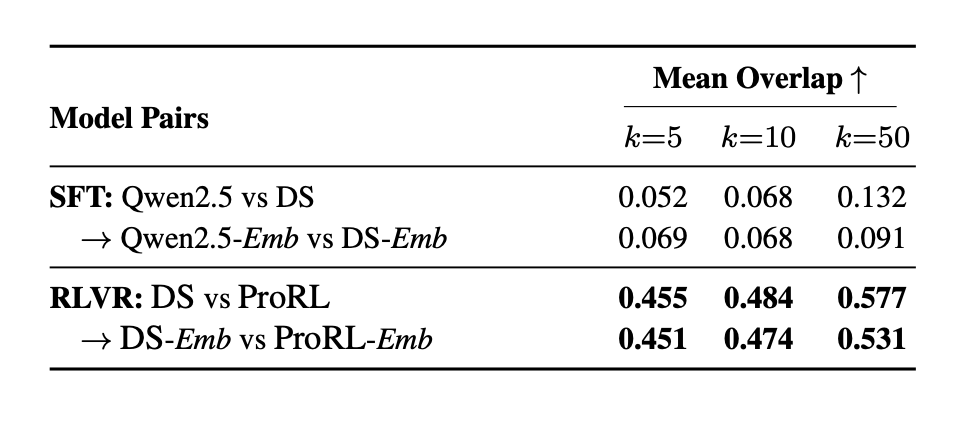
Here’s the kicker: When these RLVR-tuned models are then adapted into embedding models through contrastive learning, something remarkable happens. It’s like the head librarian (contrastive learning) comes in and ensures that all versions of the library, whether from the base model or the RLVR-tuned model, are aligned and intuitive for users. The system re-algin, effectively overwriting the reversible drifts and aligning the embedding spaces (except for the irreversible local geometry reorganization).
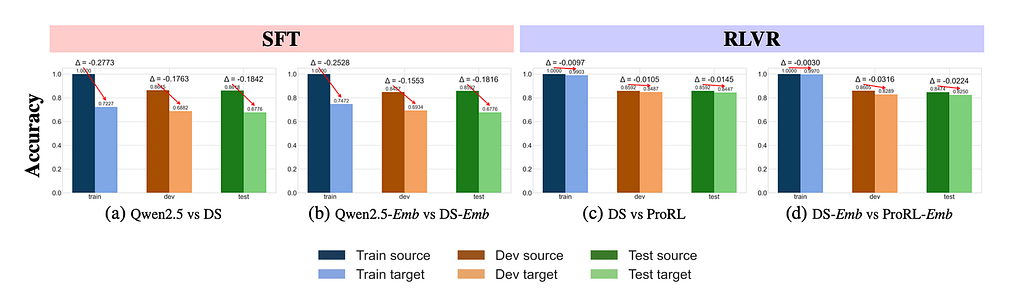
The beauty of Manifold Realignment is not just theoretical; we can see it happening. Observe the training dynamics in the figure below:

This chart visually demonstrates how quickly the models’ representations realign during contrastive learning. At Step 0 (the LLM backbone), there might be some differences. But as contrastive learning progresses, the representational similarity rapidly increases and stabilizes. This “realignment” ensures that despite the local tweaks made by RLVR, the models converge to highly similar and effective embedding spaces.
As you can see, even though RLVR can induce coordinate basis drift, contrastive learning acts as a powerful aligning force, ensuring the global semantic structure and linear readouts remain robustly consistent across base and reasoning-tuned models.
What does this mean for you, the developer or researcher building with LLMs?
This research suggests that RLVR primarily optimizes how models traverse an existing semantic landscape, rather than fundamentally redrawing it. This is incredibly important because it means:
Our HRSA framework itself is a significant contribution, providing a new toolkit for interpretability studies, allowing us to disentangle how different training methods reshape the internal workings of AI models, and organizing the messy RSA framework. This insight opens doors for future training designs , perhaps even achieving similar effects to RLVR with geometry-aware regularization in SFT.
In essence, you get the best of both worlds: a smarter, more capable reasoning model, whose rich semantic representations remain fully effective for embedding tasks.
Paper: https://www.arxiv.org/abs/2601.21192
Codes: https://github.com/HKUST-KnowComp/Reasoning-Embedding
Models and data: https://huggingface.co/collections/lucaswychan/reasoning-embedding